Collection Analysis
Sawood Alam, Computer Science, Old Dominion University
Gil Hoggarth, Web Archiving, British Library
Mat Kelly, Computer Science, Old Dominion University
Jessica Ogden, Web Science, University of Southampton
Shawn Walker, Information Science, University of Washington
Dawn Walker, Information Studies, University of Toronto
Our group came together around an interest in how to assess what's missing in web archives. We're an interdisciplinary group and a mix of both researchers and web archivists with methodological interests in ways to quickly assess the presence or absence of URLs and domains within web archival collections.
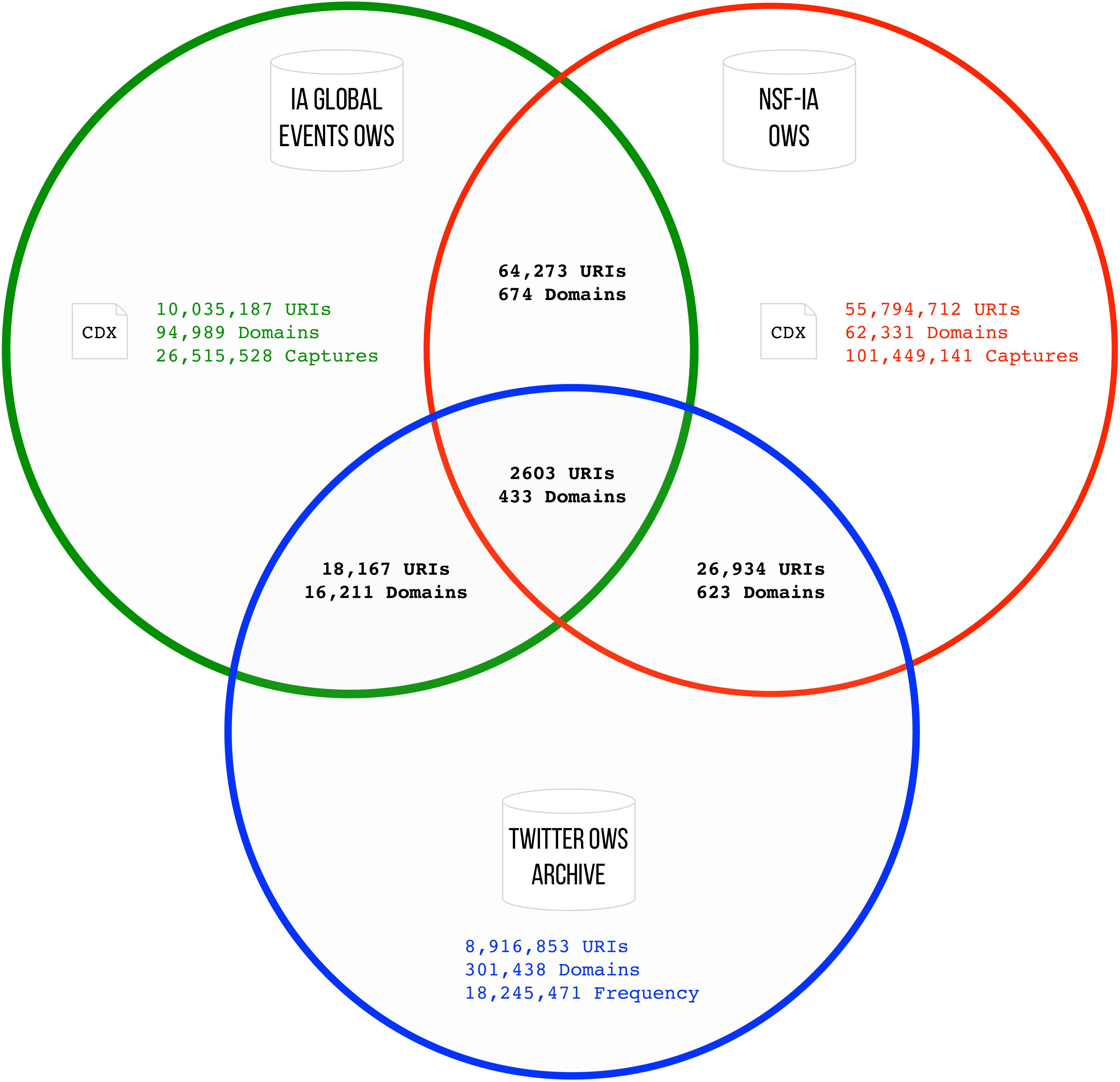
Given the availability of data, we chose Occupy Wall Street as a case study for assessing the above across multiple collections. Occupy Wall Street (OWS) is the name given to a protest movement that began on September 17, 2011, in Zuccotti Park, located in New York City's Wall Street financial district, receiving global attention and spawning the movement against economic inequality worldwide (source: https://en.wikipedia.org/wiki/Occupy_Wall_Street).
Produce a set of recipes and metrics for assessing and calculating URL, domain coverage across web archives. This is relevant for issues of archival staffing, labour and efficiency, redundancy (and ramifications for resources), the presence/absence of domains and inherent issues of selection and representativeness in the preservation of web resources.
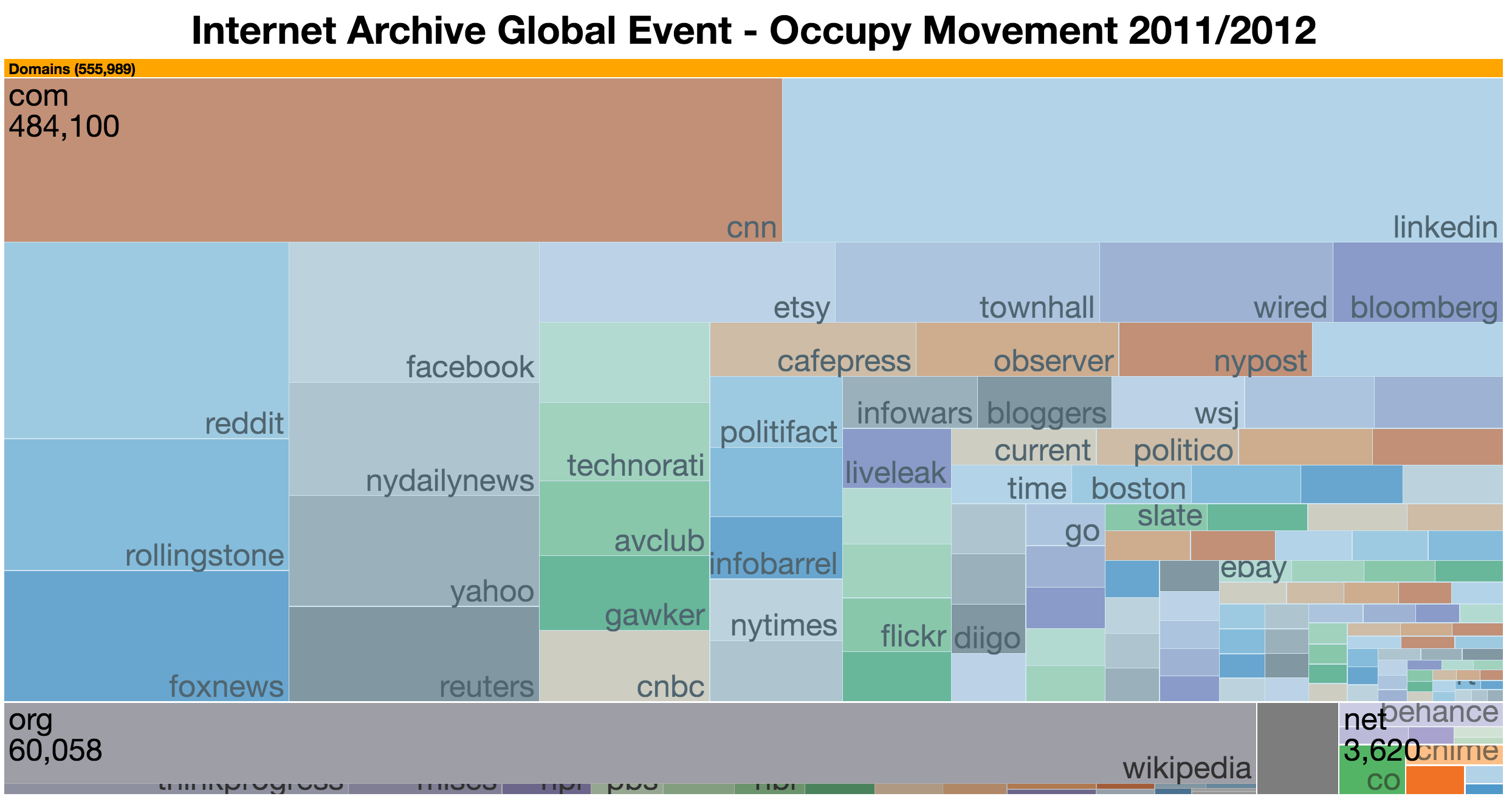


The study quite clearly demonstrates that even in collections where we might expect to see a lot of overlap in the domains/URIs collected, little overlap is present. Whilst the challenges still persist around resource constraints in web archiving (space, labour, funding), some forms of redundancy in the effort required to collect and maintain these web archives is still required.
The study confirms the lack of overlap between web archives and social media URLs (e.g. things that are shared on Twitter). This reinforces existing research around the difference in those resources indicated as ‘important’ between collection/curation practices - e.g. masses vs ‘gatekeepers’ (Milligan et al, 2017).
Whilst we didn't have time to produce an indepth cookbook for assessing the intersection of web archives, we managed to do a lot of number crunching and archival visualisation in a relatively quick amount of time. In the future we could examine different collection mechanisms/tools, and the ratios of ‘success rates’ between crawler types/tools - by using filetype distributions and status codes to indicate whether certain crawlers (on same URLs) were ‘more successful’ in the capture of live resources.